Updated: 3. nov-23
Foreword
At first, i will only focus on text generation so that you have a working chat ai working.
Later i will update this topic with the instructions for image generation, text to speech and so on (As i learn about them myself).
Even though im a software engineer, i am not advanced with any of these tools yet, and i dont know a lot about them. I will try to help you out as much as i can.
I have written this over a couple of days, and i hate rereading things i've already written. So there are probably quite a few mistakes or unclear instructions. Let me know, and ill fix them.
If you want to get into these tools, i will highly recommend you to read more about it on your own. Some of the tools have a discord or reddit where you can ask questions or get help, just remember to keep it SFW (Safe for work). In most of these places NSFW is not allowed.
SillyTavern have a discord server where you need to be a member for 7 days until you get access to NSFW channels.
If you have never played with any of these tools before, it will probably take you a lot of time to get working. I've tried to be as descriptive as possible. It can be infuriating setting up, but it is worth it in the end. I would guess it would take a technical person roughly 10 hours to setup, and way faster for a power user. It would be impossible for non-technical people.
There should also be a few youtube videoes for those who prefer that.
I found a tool called "AI-Toolbox" which is probably not well known, so you will probably not find any guides on how to use this to install all of the other AI applications.
First, you should probably check your computer. RAM is a heavy must. The AI applications will load your selected model into your RAM so it does not have to load the models from your drive every time it has to generate a response. This will most likely take up 4-12 GB RAM. I have 24 GB RAM, and it is sometimes running at 22-23 GB usage (With both text and image generation running idle)
Also, your graphics card should have 10+ GB VRAM, if any lower you could be constantly running into "out of memory" errors.
I am using a 1080 TI 11GB, and with my current settings i havent run into "out of memory" in a while.
Again, you need to spend time learning everything, use google, youtube etc..
Useful links
- Spoiler: show
-
SillyTavern documentation: https://docs.sillytavern.app/
Github links:
SillyTavern: https://github.com/SillyTavern/SillyTavern
SillyTavern-Extras: https://github.com/SillyTavern/SillyTavern-extras
Obabooga/text-generation-webui: https://github.com/oobabooga/text-generation-webui
stable-diffusion-webui: https://github.com/AUTOMATIC1111/stable-diffusion-webui
Places to find AI Models:
Civit AI: https://civitai.com/models
Hugging Face: https://huggingface.co/models
Premade SillyTavern characters
ChubAI: https://www.chub.ai/
Terminology
- Spoiler: show
-
Explainers
- Spoiler: show
-
AI model
- Spoiler: show
-
There are different types of AI models, they all have their own purpose.
The types we often hear about is "Text Generation" and "Image Generation"
ChatGPT is running a "Text Generation" AI
The AI "Predicts" the output based on the model.
For text generation this means that, the AI will try to predict the next sequence in a given text.
If the model was trained on Harry Potter books, the AI would try to predict the next sequence in a Harry Potter style.
If the model was trained on erotic novels, the AI would output erotic fashioned text.
For image generation the AI will try to predict what an image will look like for the given prompt/text.
If the image generation model was trained on cartoon images, the output image would be a cartoon image.
If the image generation model was trained on porn pictures it would output porn style images.
One way you could this of models "The model is the AI's style"
Also, gotta mention. If the model was not trained on erotica or nudity, the AI would not be able to output that kind of content. Because the AI does not know what a concept is, then it cant correct its output accordingly.
For instance if the Image generation model was never exposed to images of boobs then it would not know how to output an image for your prompt that includes "large boobs"
The same goes for text generation model, if it was never exposed to the word "dildo" it would not know what that means.
Last thing, your AI is not learning or training over time as you use it.
It has to be specifically trained on your use of it if you want it to learn.
The model is a checkpoint in its training.
Think of this, as if you were to talk to your 10 year younger self, they would not know what you learning for the past 10 years they would need to go through all the same experiences you had to get that knowledge.
Summary of the different tools/applications
- Spoiler: show
-
AI-Toolbox: will automatically install all requirements for the specific AI applications.
Oobabooga/Text-generation-webui: hosts the text generation AI
Stable-Diffusion-webui: hosts the image generation AI
SillyTavern: Brings everything together, it manages your characters, communicates with the AI hosts and controls text to speech. Basically a hub that controls all the other applications.
SillyTavern-Extras: is a link between SillyTavern and extensions for stuff the developers did not want to be a part of the main application, or community extensions.
Installation
- Spoiler: show
-
We will use AI-Toolbox which is a community made tool for installing various ai applications.
At first we will install the required applications to get running. This only includes SillyTavern and text generation for now.
First we need AI-Toolbox which we will use to install the rest of the applications.
AI-toolbox
- Spoiler: show
-
URL: https://github.com/deffcolony/ai-toolbox/tree/main
1. Click the link above this text
2. Click the dropdown button with the text "<> Code"
3. Click "Download ZIP" to download the AI-Toolbox
Now that you have downloaded AI-Toolbox, you gotta extract the zip file into a folder. This folder will be your installation location for all of the different AI applications.
Keep in mind that all of the AI applications together can easily take up over 100GB. And also which drive you use, the speed of the drive has a huge effect on the applications. The AI's will need to read the models which sometimes take up 10GB.
4. Extract the ZIP file to your preffered installation location
5. Now you should have AI-Toolbox installed and be ready to install the AI applications.
I will now refer to this installation location as "AI-Toolbox root", for me the AI-Toolbox root is "E:\ai-toolbox-main" and i will use my own paths as examples for describing which folder i am talking about.
SillyTavern & Textgen/oobabooga/text-generation-webui
- Spoiler: show
-
Navigate to the SillyTavern folder inside of your AI-Toolbox root. "E:\ai-toolbox-main\sillytavern"
This folder includes 5 files, an icon and two install scripts for both Windows and Linux.
.bat for windows
.sh for linux
1. Run the st-install file for your system (st-install.bat for windows)
It will open a console window and ask what you want to install.
You will need to type a number and press enter (just like with TeaseAI), to confirm your choice.
It will throw an error saying something like "Windows cannot find vs_buildtools.exe"
Just click OK to this error. I made a bug report about this: https://github.com/deffcolony/ai-toolbox/issues/2
I am not sure what it is for, if you run into any problems with running SillyTavern or its features this could be potential cause for your problem.
In short, there is something that is not being installed, and i dont know if it is needed.
It will install all the required tools to run SillyTavern and SillyTavern itself.
You can select SillyTavern + Extras if you later want to use image generation and text to speech.
After the console closes or writes "Complete" everything should have created two folders ("SillyTavern" & "SillyTavern-extras") inside the "E:\ai-toolbox-main\sillytavern".
You can run the "Start.bat" inside SillyTavern folder: "E:\ai-toolbox-main\sillytavern\SillyTavern\Start.bat"
SillyTavern does not "need" the extras to be running for the application to work.
Take a look at SillyTavern's documentation: https://docs.sillytavern.app/
Anything mentioned under the "Extras" category is gonna require the extras application to be running. The extras application is located in "E:\ai-toolbox-main\sillytavern\SillyTavern-extras"
After you have started SillyTavern it should have opened a webpage that you are hosting locally in the console window you opened. If the webpage is not opened automatically you can open it yourself in a new tab "http://localhost:8000/". It will also print the web address in the console window.
"127.0.0.1" is the same as "localhost"
Take a look around and click on everything. I will explain enough to get it running for you, but there are a lot of small settings you can adjust.
Now we will install the Text Generation AI application.
1. Run the textgen-launcher.bat file located in the Oobabooga folder "E:\ai-toolbox-main\oobabooga\textgen-launcher.bat"
2. Select the option to "Install textgen"
While waiting for text-generation-webui to install you can look further down and look for "Downloading SillyTavern Characters". It will walk you through downloading a character for SillyTavern.
When the installation is finished and you have decided if you want a shortcut for text-generation-webui the console window will navigate back to its "main menu", we will keep this console window open for now and come back to it later.
As it is starting you can download a text generation model. I recommend starting with this one: https://huggingface.co/Undi95/Xwin-MLew ... 4_k_m.gguf
Open the link and press on the "download" button to download the model file. You want to save that file to: "E:\ai-toolbox-main\oobabooga\text-generation-webui\models". All your text generation models should be downloaded into this folder.
One last thing we need to configure before starting text-generation-webui
In the text-generation-webui root folder: E:\ai-toolbox-main\oobabooga\text-generation-webui
We are going to edit the file called "CMD_FLAGS.txt": E:\ai-toolbox-main\oobabooga\text-generation-webui\CMD_FLAGS.txt
In this file if a line starts with "#" then that line is marked as a comment.
Make a new line at the bottom and add "--api" to this line. (Remember to save the file)

- oobabooga_cmd_flags_example.PNG (9.71 KiB) Viewed 12973 times
Now head back to the console we left open before (Not the one hosting SillyTavern, but the one with the main menu)
Select option "2" to run text-generation-webui
It will open a new console window that is hosting text-generation-webui.
If it fail at some point and dont continue, just close the console window and rerun textgen with the launcher script: E:\ai-toolbox-main\oobabooga\textgen-launcher.bat
It failed for me, but after rerunning it, it sucessfully started.
After sucessfully starting it should look like:
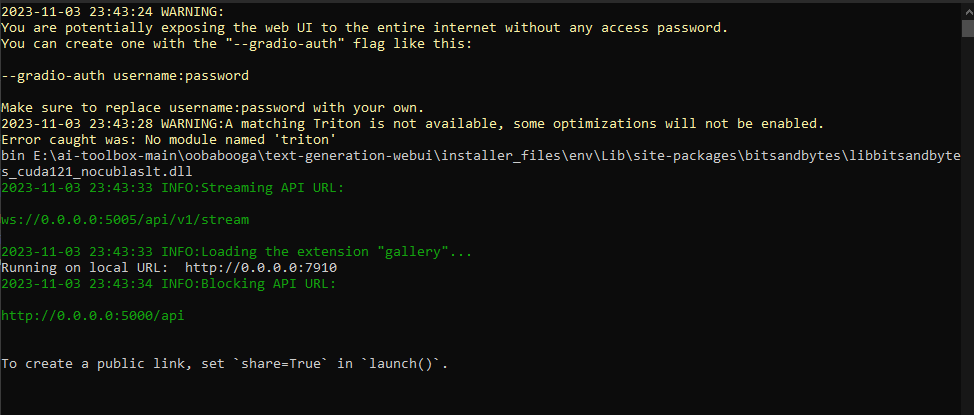
- oobabooga_startup_example.PNG (26.54 KiB) Viewed 12973 times
Notice it says "Running on local URL: http://0.0.0.0:7910"
It might say "localhost" "127.0.0.1" but all these just references that it is running on your own computer.
The numbers after ":" is the port that the web page is running on. They might be different for you.
Open the textgen web page with your browser.
First head to the "Model" tab at the top.
1. Then open the dropdown menu at the top. Select the Xwin-MLewd model you downloaded before (This is where we select which AI model we want to use).
2. Make sure that where it says "Model Loader" the option "llama.cpp" is selected.
3. You will need to set the options in the small window with "n-gpu-layers" and "threads"
You can read about all the different options here: https://github.com/oobabooga/text-gener ... b#llamacpp
Notibly you should set "n-gpu-layers", "threads" & "threads_batch" according to the link i mentioned above.
Here is a screenshot of the settings i have used.
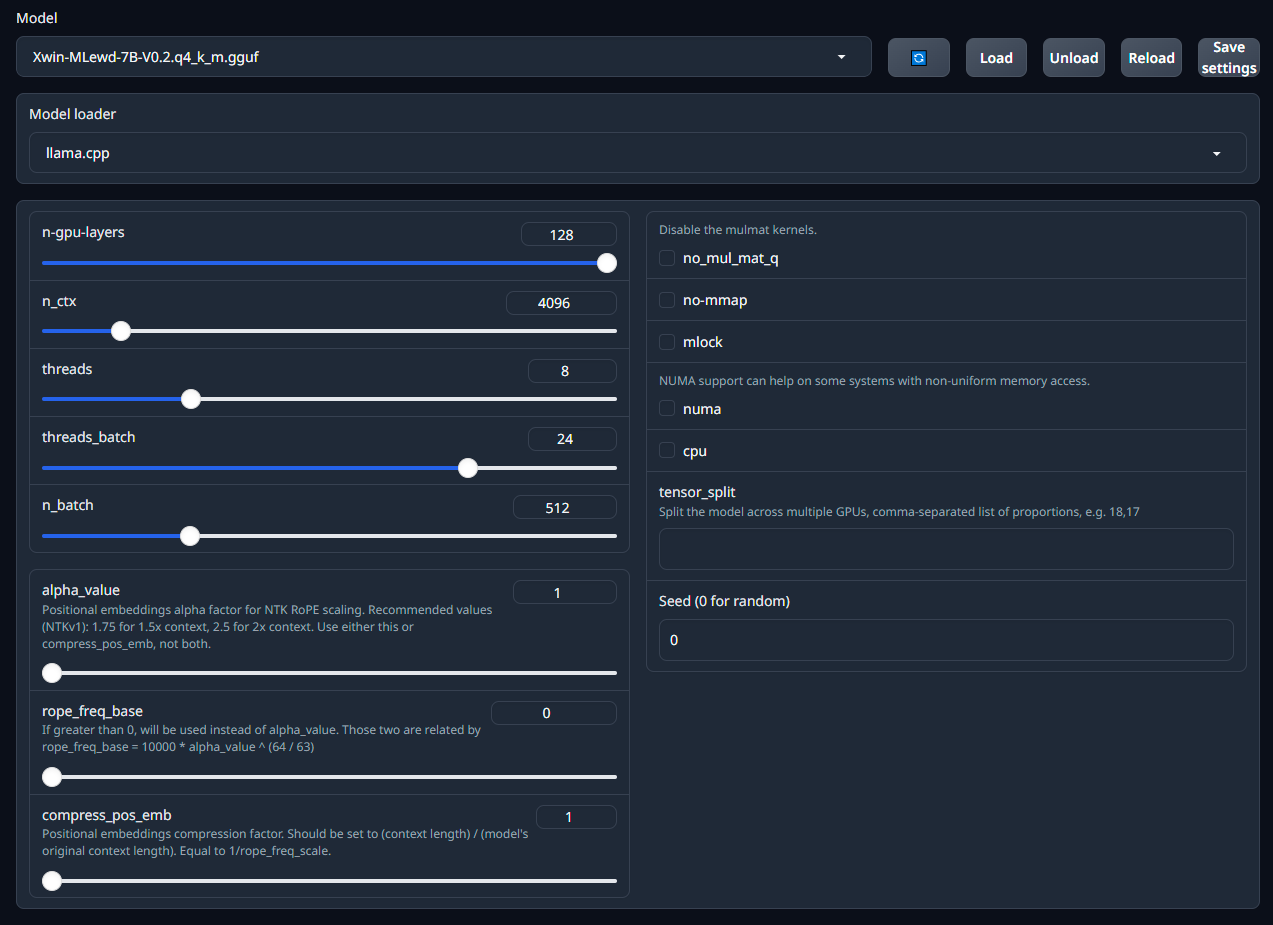
- oobabooga_model_settings_example.PNG (96.29 KiB) Viewed 12973 times
What is cores?
- Spoiler: show
-
It references your CPU cores. I use a Ryzen R7 1800x, it has 8 cores.
The virtual cores is generally double the amount of physical cores.
You can easily see how many cores you have.
If you press ctrl+alt+delete and click on the "task manager".
Head to the "Performance" tab and select "CPU"
Then it mentions how many cores and virtual cores you have. I have outlined them in the following screenshot.
"Cores" is your CPU's physical cores, "Logical processors" is your CPU's virtual cores.
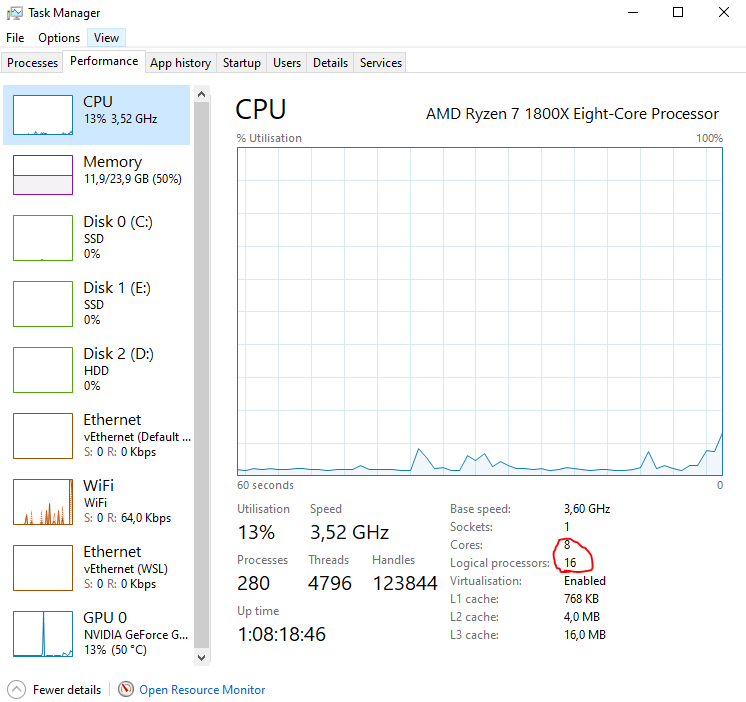
- task_manager.PNG (42.33 KiB) Viewed 12973 times
After you have set the values accordingly. You can press the button "Save Settings" so the values will be saved.
Finally you will need to press "Load" to load the actual model.
Now we just need to connect SillyTavern to the textgen application.
Back in SillyTavern we can open the connection tab.
Remember to select Text Gen WebUI for the API.
Then you should be able to click connect.
If it is successfully connecting the red dot at the bottom will turn green.

- sillytavern_connect.PNG (59.39 KiB) Viewed 12973 times
The blocking api url and streaming api url, you can double check those urls by taking a look at the textgen console window.
Scroll to the top of the console.
It mentions the urls that you are supposed to use in SillyTavern.
- oobabooga_startup_example.PNG (26.54 KiB) Viewed 12973 times
In the screenshot it mentions these two urls:
Blocking API URL: http://0.0.0.0:5000/api
Streaming API URL: ws://0.0.0.0:5005/api/v1/stream
When you are connected, you can select a character from the character list, you should already have downloaded one.
When a character is selected, it should display a chat window and a opening message in the chat.
You can respond to it, and the AI should take a few seconds to respond.
Downloading SillyTavern Characters
- Spoiler: show
-
Head over to https://www.chub.ai/ and find a character you want to try out, remember to turn on the NSFW at the top to show NSFW characters.
When you are on the character page, you click on the purple button that says "V2" that should download a .png file. I outlined the button on the screenshot.

- aerjhaerh.PNG (427.91 KiB) Viewed 12973 times
Now that you have downloaded the character png you can import this into SillyTavern.
Open the character list window in SillyTavern and click the import character button. I outlined the buttons in the screenshot.

- arejrfgtjsnrts.PNG (68.84 KiB) Viewed 12973 times
Now your new character should be ready to use.
The character information, description etc.. is embedded in the .png file. So the .png is not just an image it is the entire character.




